
Préambule : Kesako le dédédé ?
Le Domain-Driven Design a été formalisé par Eric Evans dans un livre datant de 2003 et qui fait référence encore aujourd'hui : Domain-Driven Design, Tackling Complexity in the Heart of Software.

Pour faire court, il s'agit d'une méthodologie de conception d'applications proposée par Evans visant à mettre le métier à modéliser au coeur de cette conception, dans le cadre d'un échange soutenu et régulier entre équipes techniques et experts du métier.
Cette méthodologie repose sur plusieurs concepts de haut niveau qui sont les piliers du DDD : le langage omniprésent ("ubiquitous language"), l'acquisition du domaine, la cartographie d'ensemble de l'application et le découpage en contextes bornés ("bounded contexts"), les itérations et le raffinement continu (distillation), etc. Elle propose également aux développeurs des modèles et des pratiques concrètes pour modéliser au mieux un domaine métier ; ce sont par exemple les blocs constitutifs d'une conception métier, tels que les entités, les value objects, les services, les fabriques, les repositories, ainsi que les architectures en couches, etc.
Et depuis 2003 ?
Le livre d'Evans a été publié en 2003. Entretemps, les développeurs se sont approprié les pratiques pronées dans le livre et ont également enrichi sa pratique avec de nouvelles approches (en particulier, l'architecture hexagonale, l'event sourcing ou le CQRS). Pour autant, de nombreux concepts présentés dans ce livre demeurent tout-à-fait pertinents et applicables aux applications métiers d'aujourd'hui
Le DDD vite fait
Le livre d'Evans compte près de 600 pages et n'est pas forcément d'une lecture facile. Il en existe une version résumée : http://seedstack.org/pdf/DDDViteFait.pdf
Le DDD : un modèle vertueux ?
Un des leitmotivs du DDD recommande de structurer son code pour qu'il colle au plus près du métier. En particulier, les concepts du métier doivent transpirer dans votre code, en adoptant par exemple des noms de packages, de classes ou de méthodes qui sont le reflet des concepts et des actions du métier.
De même l'organisation de votre code (les bounded contexts, les packages ou les namespaces) devra refléter autant que possible les grands pans fonctionnels du métier (la logistique, les ventes, les expéditions, le catalogue des produits, etc.). Un des grands avantages de cette pratique, c'est que l'acquisition de la logique métier, étape préalable avant toute intervention sur du code, constitue en soi un grand pas vers l'assimilation du code : dès lors que vous avez digéré le métier, il est plus simple de s'approprier le code écrit par un autre développeur si ce code a été organisé selon une logique métier partagée par tous, et non pas selon des considérations techniques ou très personnelles ou bien selon des conventions imposées par votre framework préféré.
Cela peut paraître évident aujourd'hui, mais avant la généralisation de la pratique du DDD, où les influences techniques ou les habitudes personnelles primaient dans la structuration et la rédaction du code, il n'était pas rare pour un développeur de devoir assimiler d'abord le métier (ce qui peut déjà constituer en soi une difficulté non négligeable, notamment lorsque les règles métiers sont complexes), puis au moment de se plonger dans le code, d'essayer de deviner comment ses prédécesseurs avaient traduit ce métier dans leur code. Pirouette intellectuelle très dispensable, qui ne faisait qu'ajouter de la complexité, de manière totalement artificielle ! Le DDD tend à gommer au maximum les écarts pouvant exister entre le métier et votre code et ça n'est pas la moindre de ses vertus.
A propos de l'acquisition du métier
Les concepts importants du métier n'apparaissent pas toujours dès le début de l'analyse du métier, notamment lorsque ce métier est complexe ou fonctionnellement riche. Il faut parfois plusieurs itérations avant de dessiner de manière satisfaisante les frontières des différents pans fonctionnels, identifier le coeur de métier, assimiler et modéliser finement une partie du métier un peu complexe ou bien dégager les concepts essentiels. C'est ce long processus de révélation et d'acquisition qu'Evans appelle la distillation, et ce travail peut parfois faire émerger en cours de route un concept métier qui n'était pas apparu clairement au départ. Et Evans recommande bien évidemment de faire évoluer ou restructurer son code chaque fois que les frontières s'affinent ou lorsqu'un concept métier essentiel se révèle tardivement, pour maintenir un code aussi proche que possible du modèle métier à mesure qu'il s'affine.
Vous avez peut-être croisé au cours de votre carrière des projets dont le code source s'articulait autour des namespaces (ou packages) Domain|Application|Infrastructure : il s'agit sans aucun doute de projets inspirés du DDD et des architectures en couches telles que l'architecture hexagonale, l'onion architecture ou la clean architecture définie par Robert C. Martin (aka Uncle Bob), qui préconisent d'isoler le code modélisant le métier et de limiter au maximum l'adhérence de l'environnement technique (bases de données, frameworks, contexte d'exécution, etc.) sur ce code métier.
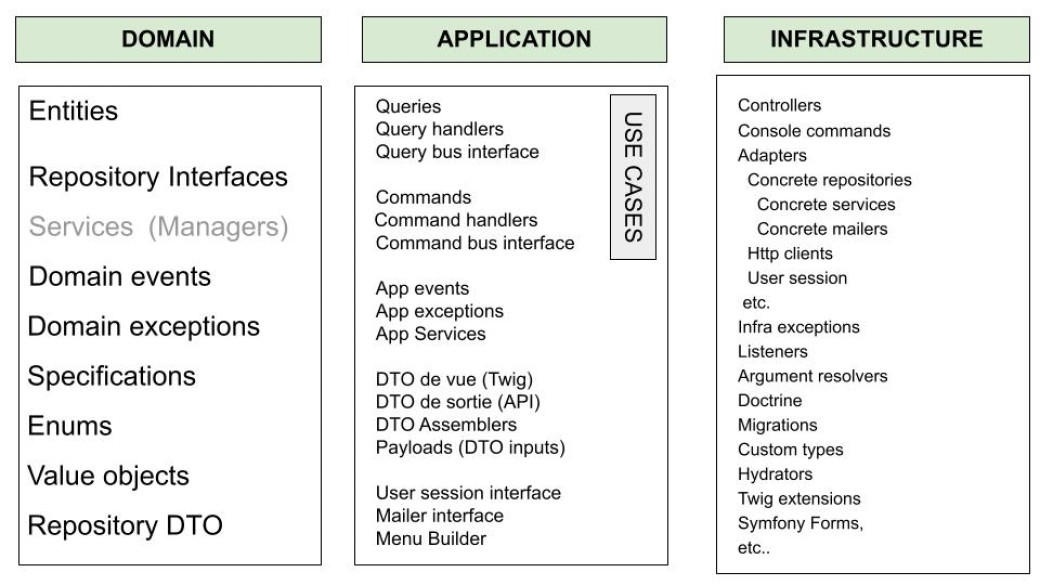
Le schéma ci-dessus propose une ventilation possible de vos classes métiers et techniques dans les différentes couches du DDD. Cela reste une proposition, rien n'est bien entendu inscrit dans le marbre, même si certaines classes objet, selon leur nature et leur rôle, ont nécessairement une place naturelle.
Pour essayer de présenter ces trois couches aux débutants, j'ai pour habitude de les décrire de la manière suivante :
-
la couche
Domaincontient les classes qui décrivent le métier dans ses aspects plutôt statiques et structurels ; c'est notamment ici que l'on retrouvera les entités qui modélisent les principaux concepts du métier ainsi que les interfaces de repositories qui permettent d'y accéder (pour les afficher dans des listes, les présenter, les créer ou les modifier). On trouve également de manière assez naturelle toutes les classes dont ces entités ont besoin et notamment les value objects et les énums qui sont la plupart du temps des propriétés de ces entités ; -
la couche
Applicationcontient les classes qui modélisent le métier dans ses aspects plutôt dynamiques. C'est notamment ici que l'on trouvera les commandes et les queries qui correspondent aux cas d'utilisation applicatifs (au sens UML, use cases), ce que l'on appelle parfois des scénarios (exemple : "en tant que client, je peux consulter la liste de mes commandes en cours"). On peut également y trouver tout ce qui relève de l'application, comme par exemple des classes qui permettent de construire les menus de l'application, considérant qu'un menu relève de l'applicatif et pas vraiment du métier qu'on modélise ; -
la couche
Infrastructurecontient toutes les classes qui ont des dépendances sur l'environnement d'exécution ou l'outillage technique tel que les bases de données, les API tierces, ou bien le framework par exemple. On y trouvera en particulier les adapteurs, c'est-à-dire les implémentations concrètes des interfaces définies dans les couches supérieures (Domain et Application). En effet, le DDD recourt intensivement aux interfaces pour permettre de définir de manière abstraite des comportements et ainsi limiter au maximum les aspects purement techniques dans les couches supérieures. L'exemple le plus courant est la définition d'interfaces de Repository dans le domaine pour exposer des méthodes de récupération, de suppression, de création ou de mise à jour des entités, tandis que les implémentations concrètes, qui dépendent de la base de données ou d'un ORM, sont elles définies dans la coucheInfrastructure. Le DDD préconise de séparer autant que possible les concepts métiers et les contraintes techniques, et à ce titre, les interfaces jouent un rôle essentiel.
Contexte d'exécution
Les couches Application et Domain doivent être complètement agnostiques du contexte d'exécution. En particulier, elles ne doivent jamais faire référence à des concepts HTTP (méthodes HTTP, paramètres GET, etc.) et devraient pouvoir s'exécuter indifféremment dans un contexte HTTP, en ligne de commande, ou dans des tests unitaires.
Notez que plus une classe se situe dans une couche élevée (Domain ou Application), plus elle est abstraite. Par exemple, si votre application communique avec un CRM comme Hubspot, vous aurez sans doute à définir dans Domain ou Application une interface que l'on nommera CRMServiceInterface (notez que le nom de l'implémentation concrète, Hubspot, ne transpire pas dans le nom) et qui aura pour implémentation concrète (adapteur) une classe HubspotService qui implémentera toutes les méthodes attendues par l'interface.
Idéalement, une couche supérieure ne devrait pas dépendre d'une couche inférieure ou d'une dépendance tierce (le dossier vendor d'un projet PHP). Les couches Application et Infrastructure peuvent dépendre de Domain, mais inversement, Domain ne doit pas dépendre de la couche Application ou Infrastructure (de même, Application peut dépendre de Domain, mais pas d'Infrastructure, considérée dans le DDD comme la couche la moins "noble"). Là encore, les interfaces jouent un rôle essentiel. Si vous parvenez à réduire (voire mieux, supprimer) les dépendances du haut vers le bas, c'est signe que votre code respecte un des principes premiers du DDD, à savoir séparer le code métier du code technique.
Au final, cette manière de structurer votre code apporte énormément de lisibilité à votre application. Quels sont les principaux concepts métiers à l'oeuvre ? Consulter le contenu de la couche Domain permet de le savoir assez aisément. Et quels sont les différents scenarios applicatifs qu'implémente l'application ? La couche Application vous renseignera. Et je trouve que cette lisibilité est bénéfique à toute l'équipe et permet notamment une meilleure prise en main pour les développeurs amenés à intervenir sur le projet. On parle souvent d'architectures expressives (screaming architectures) au sujet des projets qui respectent ce découpage. En effet, la structure du code permet de mieux appréhender le métier modélisé, sans se noyer dans les détails techniques, rejetés au second plan.
En outre, ce découpage a un autre avantage : il permet notamment de faciliter l'écriture des tests. En effet, les classes des couches Domain et Application seront d'autant plus faciles à tester qu'elles n'ont pas de dépendance sur l'infrastructure. Comme elles se basent sur des interfaces et non pas des implémentations concrètes, il suffira de mocker les dépendances.
Enfin, sachez que le DDD s'appuie énormément sur les bonnes pratiques de la Programmation objet (interfaces, conception SOLID, etc.) et cohabite très bien avec d'autres méthodologies de développement telles que le TDD (Test Driven Development) ou le BDD (Behavior Driven Development). Il ne constituera donc en rien un frein si vous êtes friands de ces pratiques.
Les principaux écueils
A la base, le DDD a été conçu pour s'appliquer à des projets d'une certaine envergure et/ou d'une certaine complexité. Chez elao nous l'avons adopté sur la plupart de nos projets, indépendamment de ces critères, car nous apprécions vraiment ses apports et il garantit une certaine homogénéité entre tous nos projets et facilite ainsi leur prise en main.
Si cet article peut vous inciter à franchir le pas en adoptant le DDD dans vos projets, il aura atteint son objectif. En revanche, avant de se lancer, il faut être conscient de certains écueils pour que votre expérience ne s'avère pas contre-productive.
Comme cet article le laisse penser, le découpage de votre code est primordial. Cela signifie qu'une phase de réflexion en amont est souvent nécessaire pour organiser votre code avant même l'écriture de la première ligne. Si l'application que vous développez est fonctionnellement riche, il sera nécessaire d'identifier de grands pans fonctionnels ainsi que les concepts métiers susceptibles d'être rapprochés entre eux. Si vous développez par exemple un site d'e-commerce, vous identifierez sans doute de grands pans fonctionnels tels que la navigation dans le catalogue, le tunnel de commande, la gestion clients, les opérations logistiques, etc. Cela nécessite bien entendu de prendre un peu de hauteur par rapport aux spécifications métiers et requiert une certaine capacité à voir plus large.
Une fois que vous aurez identifié ces grands périmètres fonctionnels, il faudra également identifier les concepts forts à l'intérieur de ce cadre. Rien de pire et de plus déroutant à mon sens que les projets qui contiennent dans leur dossier Entity plusieurs dizaines d'entités à plat, sans faire transpirer la moindre hiérarchie. Un code bien organisé c'est aussi un code qui met en avant les concepts forts du métier et rejette au second plan ce qui mérite de l'être.
Comme nous avons également pu le voir, le DDD et les architectures en couches recourent fréquemment aux abstractions. Là encore, le découpage objet et la répartition des responsabilités entre classes nécessite une certaine maturité de la part des équipes. Le DDD ne s'adresse clairement pas à des équipes peu expérimentées ou tout du moins peu motivées à l'idée franchir le pas. En particulier, il n'est pas toujours évident de mettre en oeuvre les mécanismes qui permettent de réduire les dépendances entre couches, mais les automatismes s'acquièrent finalement assez rapidement, il s'agit juste d'une gymnastique à assimiler.

Il faut également savoir que la mise en oeuvre des architectures en couches tend à augmenter le nombre de lignes de code produites. Cela peut bien entendu avoir un impact sur la productivité des équipes, mais chez elao nous considérons que c'est un inconvénient bien négligeable au regard du bénéfice. En effet, la structuration du code facilite sa maintenance et apporte donc un gain très important sur le moyen terme. De plus, les habitudes acquises dans la production de code orienté DDD compensent en grande partie la baisse de productivité induite par l'augmentation du nombre de lignes de code à écrire.
Le DDD place le métier au coeur de la conception et il importe donc de raisonner métier au moment d'écrire son code, et de s'affranchir autant que possible des contraintes techniques. Ce qui doit primer dans l'écriture de code, ce sont les concepts métiers et il faut donc accepter de renoncer à certaines habitudes, comme par exemple penser son code comme une simple interface autour de la base de données. Désormais, je n'écris plus du code pour enregistrer un nouvel utilisateur en base de données, mais j'implémente le code qui permet à un nouvel utilisateur de s'inscrire (avec tous les impacts que cela peut avoir par exemple sur les noms des classes et des méthodes que j'implémente). De même, quel que soit le framework que vous utilisez, ça n'est pas à lui de dicter la manière de structurer votre code.
Enfin, comme toute pratique, le DDD compte de nombreux évangélistes parmi lesquels certains puristes. Suivre toutes les bonnes pratiques du DDD ou s'efforcer de produire un code respectueux de toutes les règles peut s'avérer épineux ou intidimidant. A titre d'exemple, on est parfois tenté de ne pas interfacer certaines classes quitte à enfreindre les règles de dépendance entre les couches, ou bien l'on a parfois besoin d'utiliser des librairies tierces dans notre Domain (je pense notamment aux collections Doctrine qui sont très utiles). Certaines personnes recommandent de ne pas utiliser le suffixe Interface dans les noms d'interface du Domain ou de l'Application, partant du principe, à juste titre, qu'il s'agit là d'une notion technique.
A titre personnel, je n'essaie absolument pas de produire à tout prix du code chimiquement pur. Bien que désireux de respecter au mieux les règles du DDD, j'accepte parfois quelques entorses, par exemple lorsque je ne souhaite pas renoncer à certaines fonctionnalités de mon framework que je juge précieuses et qui me font gagner en temps et en efficacité, surtout lorsqu'y renoncer implique énormément de torsions et d'acrobaties. J'accepte également parfois que des concepts techniques transpirent dans mes noms de classe ou dans mes noms de méthode si j'estime que cela facilite la compréhension du code et sa prise en main par d'autres développeurs.
Tendre vers un code 100% respectueux des règles du DDD peut s'avérer au final assez ardu. Le DDD présente de nombreuses vertus selon moi, et l'on peut donc y adhérer pour différentes raisons. En ce qui me concerne, j'apprécie particulièrement la production d'un code qui gagne en lisibilité, qui obéit à une organisation relativement normée et limite les fuites techniques dans le code métier. En revanche, je ne tire aucune joie particulière à produire un code parfait, pour la simple beauté du geste. Le pragmatisme à dose raisonnable n'a jamais fait de tort à personne. Vos clients sauront apprécier.